
선형 자료구조인 연결 리스트, 배열, 벡터, 스택, 큐에 대해 작성한 글입니다.
선형 자료구조 (Linear Data Structure)
선형 자료구조(Linear Data Structure)는 데이터 요소들이 선형적인 순서로 배열되어 있는 자료구조를 의미합니다. 이러한 자료구조에서는 데이터 요소들이 일렬로 연결되어 있으며, 각 요소는 이전 요소와 다음 요소로 직접적으로 연결되어 있습니다. 주요 특징으로는 데이터 요소들의 순서가 고정되어 있고, 각 요소들 간에는 순차적인 관계가 존재합니다.
연결 리스트 (Linked List)
연결 리스트(Linked List)는 데이터 요소(Node)가 데이터와 다음 요소를 가리키는 포인터로 이루어진 노드들의 집합입니다. 각 노드는 다음 노드를 가리키는 포인터(참조)를 가지고 있어서 이전 노드와 다음 노드 사이의 연결을 형성합니다. 연결 리스트에서는 데이터 요소들이 메모리에 연속적으로 저장되지 않고, 동적으로 할당된 메모리 공간에 흩어져 있습니다.
삽입과 삭제가 O(1)이 걸리며 탐색에서는 O(n)이 걸립니다.
연결 리스트에는 크게 세가지 유형이 있습니다.
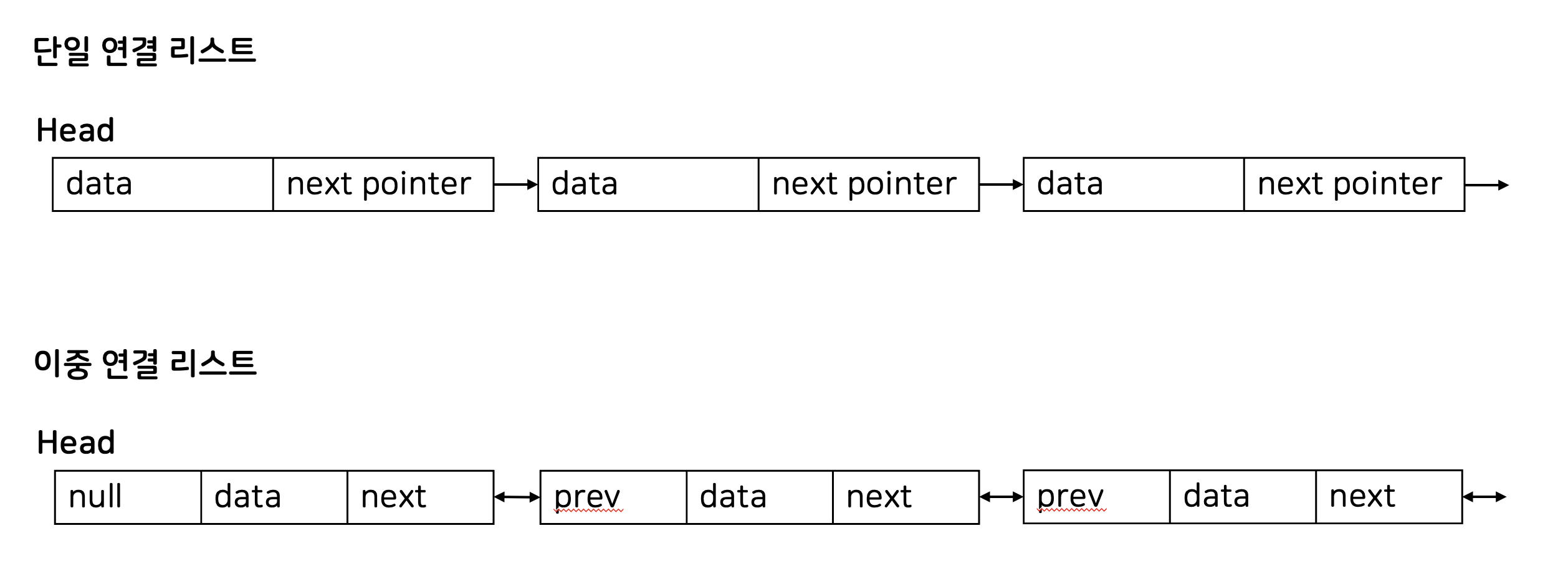
- 단일 연결 리스트: 각 노드가 데이터와 다음 노드를 가리키는 포인터로 이루어져 있습니다.
- 이중 연결 리스트: 각 노드가 데이터와 이전 노드를 가리키는 포인터와 다음 노드를 가리키는 포인터로 이루어져 있습니다.
- 원형 연결 리스트: 마지막 노드가 첫 번째 노드를 가리키는 원형 형태로 구성된 연결 리스트입니다.
원형 연결 리스트는 마지막 next가 head를 가리킵니다.
단일 연결 리스트를 자바 코드로 구현해보면 다음과 같습니다.
class Node {
int data;
Node next;
public Node(int data) {
this.data = data;
this.next = null;
}
}
class SinglyLinkedList {
private Node head;
public SinglyLinkedList() {
this.head = null;
}
// 연결 리스트에 요소 추가
public void add(int data) {
Node newNode = new Node(data);
if (head == null) {
head = newNode;
} else {
Node current = head;
while (current.next != null) {
current = current.next;
}
current.next = newNode;
}
}
// 연결 리스트 출력
public void display() {
Node current = head;
while (current != null) {
System.out.print(current.data + " ");
current = current.next;
}
System.out.println();
}
}
public class Main {
public static void main(String[] args) {
SinglyLinkedList list = new SinglyLinkedList();
list.add(1);
list.add(2);
list.add(3);
list.display(); // 출력: 1 2 3
}
}
배열 (Array)
* 정적 배열 기반으로 설명합니다.
배열은 동일한 데이터 형식의 요소들을 순차적으로 저장하는 선형 자료구조입니다. 배열은 메모리에 연속적으로 할당되며 각 요소는 인덱스를 사용하여 접근할 수 있습니다.
탬색에 O(1)이 되어 랜덤 액세스가 가능합니다. 하지만 삽입과 삭제에는 O(n)이 걸립니다.
배열은 인덱스에 해당하는 원소를 빠르게 접근해야 할 때 주로 사용합니다.
랜덤 액세스와 시퀄셜 액세스
랜덤 액세스(random access)란 데이터 구조에서 임의의 위치에 있는 데이터 요소에 직접적으로 접근할 수 있는 능력을 가리킵니다. 이는 데이터 구조에서 요소들이 연속적으로 저장되어 있고 각 요소가 고유한 인덱스를 가지고 있어 특정 인덱스를 사용하여 요소에 빠르게 접근할 수 있는 경우를 의미합니다.
순차적 액세스(Sequential Access)는 데이터 구조에서 요소들을 순차적으로 접근하는 방법을 의미합니다. 즉, 특정 요소에 접근하기 위해서는 그 이전 요소들을 순차적으로 탐색해야 함을 의미합니다. 앞서 소개한 연결 리스트가 순차적 접근 방식을 사용하기 때문에 탐색에 소요되는 시간 복잡도가 O(n)입니다.
벡터 (Vector)
벡터(Vector)"는 프로그래밍에서 동적 배열(dynamic array)을 구현하는 자료구조 중 하나입니다. 벡터는 배열과 유사하게 연속된 메모리 공간에 요소들을 저장하지만, 크기가 동적으로 조절될 수 있습니다. 즉, 배열과 달리 초기에 크기를 지정하지 않고도 요소를 추가하거나 삭제할 수 있다는 것을 의미합니다.
탐색과 맨 앞 또는 맨 뒤의 요소를 삭제하는 데 O(1)이 걸리며, 맨 뒤나 맨 앞이 아닌 요소를 삭제하고 삽입하는 데 O(n)이 걸립니다. 뒤에서부터 삽입하는 경우 벡터의 크기가 증가되는 시간 복잡도가 amortized 복잡도, 즉 상수 시간 복잡도와 유사한 복잡도를 가지고 있기 때문에 O(1)의 시간 복잡도를 가지게 됩니다.
Java에서는 java.util 패키지에 있는 Vector 클래스를 사용하여 벡터를 구현할 수 있습니다. Vector 클래스는 동적으로 크기가 조절되는 배열을 구현하며, 배열의 크기가 부족할 때마다 자동으로 크기를 조절합니다.
이 때, 자바의 Vertor 클래스는 스레드 안전(thread-safe)하도록 동기화되어 있습니다. 따라서 멀티스레드 환경에서 안전하게 사용할 수 있습니다.
스택 (Stack)
스택은 LIFO(Last In First Out)을 가진 자료 구조입니다. 즉, 가장 마지막으로 들어간 데이터가 가장 첫번째로 나오는 성질이 있습니다. 스택은 재귀적인 함수, 알고리즘에 사용됩니다.
스택에서 요소를 추가하는 작업을 "push"라고 하고, 요소를 제거하는 작업을 "pop"이라고 합니다. push와 pop 연산은 O(1)이 걸립니다. 하지만 탐색에서는 O(n)이 걸립니다.

Java에서는 java.util 패키지에 있는 Stack 클래스를 사용하여 스택을 구현할 수 있습니다.
아래 예제 코드에서는 Stack 클래스를 사용하지 않고 Stack을 구현해 보았습니다.
public class Stack {
private int maxSize; // 스택의 최대 크기
private int[] stackArray; // 스택을 저장할 배열
private int top; // 스택의 맨 위 요소를 가리키는 인덱스
// 생성자: 스택의 크기를 지정하여 스택을 초기화합니다.
public Stack(int size) {
this.maxSize = size;
this.stackArray = new int[maxSize];
this.top = -1; // 스택이 비어있음을 나타내는 값
}
// push: 스택에 요소를 추가합니다.
public void push(int value) {
if (isFull()) {
System.out.println("스택이 가득 찼습니다. 요소를 추가할 수 없습니다.");
return;
}
stackArray[++top] = value;
}
// pop: 스택의 맨 위 요소를 제거하고 반환합니다.
public int pop() {
if (isEmpty()) {
System.out.println("스택이 비어있습니다. 요소를 제거할 수 없습니다.");
return -1; // 임의의 값 반환
}
return stackArray[top--];
}
// peek: 스택의 맨 위 요소를 반환합니다.
public int peek() {
if (isEmpty()) {
System.out.println("스택이 비어있습니다. 요소를 확인할 수 없습니다.");
return -1; // 임의의 값 반환
}
return stackArray[top];
}
// isEmpty: 스택이 비어있는지 확인합니다.
public boolean isEmpty() {
return (top == -1);
}
// isFull: 스택이 가득 찼는지 확인합니다.
public boolean isFull() {
return (top == maxSize - 1);
}
// 스택의 내용을 출력합니다.
public void display() {
System.out.print("현재 스택: ");
for (int i = 0; i <= top; i++) {
System.out.print(stackArray[i] + " ");
}
System.out.println();
}
public static void main(String[] args) {
Stack stack = new Stack(5); // 크기가 5인 스택 생성
// 요소 추가
stack.push(10);
stack.push(20);
stack.push(30);
// 스택 출력
stack.display(); // 출력: 10 20 30
// 맨 위 요소 확인
System.out.println("맨 위 요소: " + stack.peek()); // 출력: 30
// 요소 제거
stack.pop();
// 스택 출력
stack.display(); // 출력: 10 20
}
}
큐 (Queue)
큐는 FIFO(First In First Out)성질을 가진 자료구조 입니다. 즉, 먼저 삽입된 데이터가 가장 첫번째로 나옵니다. 나중에 집어넣은 데이터가 가장 먼저 나오는 스택과는 반대되는 개념을 가졌습니다.
큐에서 요소를 추가하는 작업을 "enqueue"라고 하고, 요소를 제거하는 작업을 "dequeue"라고 합니다. 삽입 및 삭제에 O(1), 탐색에 O(n)이 걸립니다.
큐를 사용하면 선입선출의 특성을 활용하여 요소들을 순서대로 처리할 수 있습니다. 예를 들어, 너비 우선 탐색(Breadth-First Search, BFS)과 같은 알고리즘에서 사용됩니다.

Java에서는 java.util 패키지에 있는 Queue 인터페이스를 사용하여 큐를 구현할 수 있습니다. Queue 인터페이스를 구현한 여러 클래스 중에서 가장 일반적인 것은 LinkedList 클래스입니다. LinkedList는 이중 연결 리스트를 기반으로하여 큐를 구현합니다. 그리고 java.util.concurrent 패키지에 있는 ConcurrentLinkedQueue 클래스는 스레드 세이프(concurrent) 큐를 제공합니다.
public class Queue {
private int maxSize; // 큐의 최대 크기
private int[] queueArray; // 큐를 저장할 배열
private int front; // 큐의 맨 앞 요소를 가리키는 인덱스
private int rear; // 큐의 맨 뒤 요소를 가리키는 인덱스
private int nItems; // 현재 큐에 있는 요소의 개수
// 생성자: 큐의 크기를 지정하여 큐를 초기화합니다.
public Queue(int size) {
this.maxSize = size;
this.queueArray = new int[maxSize];
this.front = 0;
this.rear = -1;
this.nItems = 0;
}
// enqueue: 큐에 요소를 추가합니다.
public void enqueue(int value) {
if (isFull()) {
System.out.println("큐가 가득 찼습니다. 요소를 추가할 수 없습니다.");
return;
}
if (rear == maxSize - 1) {
rear = -1; // rear 인덱스를 0으로 되돌립니다.
}
queueArray[++rear] = value; // rear를 증가시킨 후 요소를 추가합니다.
nItems++; // 요소 개수를 증가시킵니다.
}
// dequeue: 큐에서 요소를 제거하고 반환합니다.
public int dequeue() {
if (isEmpty()) {
System.out.println("큐가 비어있습니다. 요소를 제거할 수 없습니다.");
return -1; // 임의의 값 반환
}
int temp = queueArray[front++]; // front를 증가시킨 후 요소를 반환합니다.
if (front == maxSize) {
front = 0; // front 인덱스를 0으로 되돌립니다.
}
nItems--; // 요소 개수를 감소시킵니다.
return temp;
}
// peek: 큐의 맨 앞 요소를 반환합니다.
public int peek() {
if (isEmpty()) {
System.out.println("큐가 비어있습니다. 요소를 확인할 수 없습니다.");
return -1; // 임의의 값 반환
}
return queueArray[front];
}
// isEmpty: 큐가 비어있는지 확인합니다.
public boolean isEmpty() {
return (nItems == 0);
}
// isFull: 큐가 가득 찼는지 확인합니다.
public boolean isFull() {
return (nItems == maxSize);
}
// 현재 큐의 내용을 출력합니다.
public void display() {
System.out.print("현재 큐: ");
int current = front;
for (int i = 0; i < nItems; i++) {
System.out.print(queueArray[current++] + " ");
if (current == maxSize) {
current = 0; // current 인덱스가 배열의 끝에 도달하면 0으로 되돌립니다.
}
}
System.out.println();
}
public static void main(String[] args) {
Queue queue = new Queue(5);
부족한 글이 도움이 되길 바랍니다. 읽어주셔서 감사합니다!
'CS' 카테고리의 다른 글
| [CS] OSI 7계층과 TCP/IP (0) | 2024.07.06 |
|---|---|
| [CS] 비선형 자료구조 그래프, 트리, 힙, 맵, 셋, 해시 테이블에 대해 알아보자 (0) | 2024.05.07 |
| [CS] 데이터베이스의 정규화 (0) | 2024.04.17 |
| [CS] 토큰 기반 인증과 JWT (0) | 2024.04.12 |
| [DB] 트랜잭션과 ACID, 데이터의 무결성 (0) | 2024.03.31 |